
沒接觸 AI 前,儲存對話只會透過 SQL 或 NoSQL 資料庫儲存對話內容,查詢資料也只能使用關鍵字搜尋,只要關鍵字不同就無法搜尋到內容,而昨天提到向量資料庫會先將文字向量化在儲存,並使用近似值搜尋的方式讓我們可以將語意相近的內容也一併找出,除了更容易找出資料外也不會有數量限制,因為查詢的內容是根據整個對話的資料搜尋
竟然這麼好用,趕緊來實作吧,程式只需要把 Day19 的 MessageChatMemoryAdvisor 改成 VectorStoreChatMemoryAdvisor 即可,因為 VectorStoreChatMemoryAdvisor 還需要傳入向量資料庫的變數,所以我們需要先宣告變數讓 Spring 幫我們注入
昨天設定 Neo4j 的部分記得也要更新在專案上,Spring 才能幫我們建立 VectorStore 的 Bean
@RequiredArgsConstructor
@Service
public class ChatService {
private final ChatClient chatClient;
private final VectorStore vectorStore; //Spring 會幫我們建立 Bean,並自動注入
public String chat(String chatId, String userMessage) {
return this.chatClient.prompt()
.advisors(new VectorStoreChatMemoryAdvisor(vectorStore, chatId, 100), new TokenUsageLogAdvistor())
.user(userMessage)
.call().content();
}
}
VectorStoreChatMemoryAdvisor 的參數說明如下
趕快來驗證成果吧
咦?哪裡出了問題,透過向量資料庫反而查不到內容,上 Spring AI 的 Github 才發現原來這是 bug 阿,https://github.com/spring-projects/spring-ai/issues/800
Bug description
When using PGvector as vector store for VectorStoreChatMemoryAdvisor to save conversation history, there is org.postgresql.util.PSQLException "ERROR: syntax error at or near "conversationId"". The problem happens because in adviseRequest method in VectorStoreChatMemoryAdvisor single quotes added around DOCUMENT_METADATA_CONVERSATION_ID , which causes an error when parse it in JDBCTemplate.
var searchRequest = SearchRequest.query(request.userText())
.withTopK(this.doGetChatMemoryRetrieveSize(context))
.withFilterExpression(
"'" + DOCUMENT_METADATA_CONVERSATION_ID + "'=='"
+ this.doGetConversationId(context) + "'");
看到這個 Issue 還蠻傻眼的 DOCUMENT_METADATA_CONVERSATION_ID 一看也知道是常數,怎麼會被當成文字來組 Filter,不過凱文大叔還是得讓大家看到測試結果,在官方還沒更新前只好自己 Debug 了,原本想直接繼承 VectorStoreChatMemoryAdvisor 再覆蓋有問題的方法,不過程式中許多常數都設為 private,所以乾脆直接複製一個新的 MyVectorStoreChatMemoryAdvisor 完整程式碼可以在下面的 Source Code 查到,更改的內容如下
var searchRequest = SearchRequest.query(request.userText())
.withTopK(this.doGetChatMemoryRetrieveSize(context))
.withFilterExpression(
DOCUMENT_METADATA_CONVERSATION_ID + "== '" + this.doGetConversationId(context) +"'");
另外針對近似值查詢凱文大叔也稍微調整一下程式
List<Document> documents = this.getChatMemoryStore().similaritySearch(searchRequest);
String longTermMemory = documents.stream()
.map(Content::getContent).distinct()
.collect(Collectors.joining(System.lineSeparator()));
近似值查詢出來的格式為 List<Document> documents,由於 Document 除了 context 還包含 metadata,如果要將歷史對話組成字串可透過 map 的方式快速重組,上面這段內容凱文大叔只加了 .distinct(),做這個小小調整主要是程式剛上線或是測試時用戶一定會問很多重複資料,透過這小小的修改就能將重複的內容過濾掉,減少我們送給 AI 的 Token 數量
最後將 ChatService 中的 Advisor 改成自己改寫的就大功告成了
.advisors(new MyVectorStoreChatMemoryAdvisor(vectorStore, chatId, 100),
new TokenUsageLogAdvistor())
透過 Neo4j 網址也能看到每個對話節點: http://localhost:7474/browser/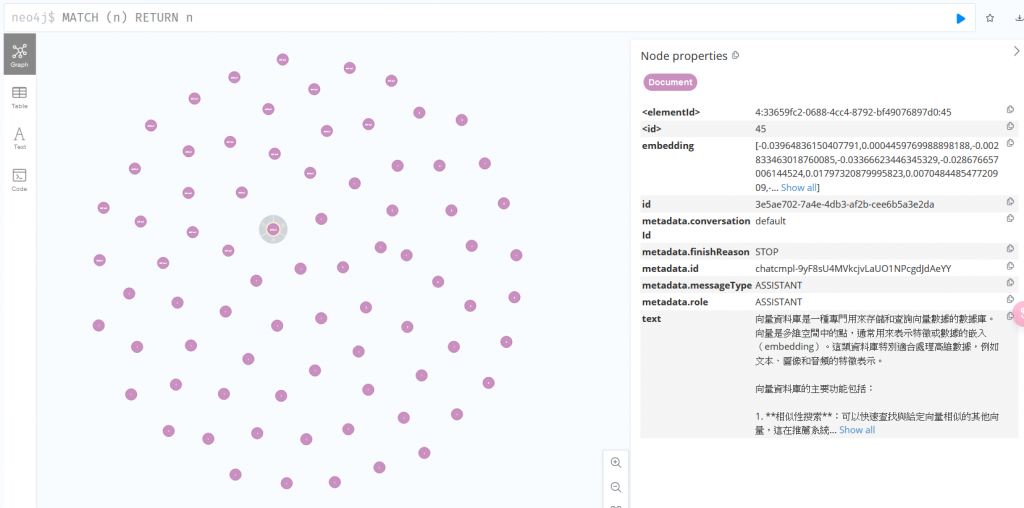
雖然 AI 的回答似乎能參考歷史訊息,不過與前面的短期記憶有點出入
凱文大叔測試完有以下心得
利用向量資料庫儲存對話內容更適合用來查詢訊息而不是用作對話記憶
雖然 VectorStoreChatMemoryAdvisor 有 bug,使用起來也不太順手,不過卻給我們一些不錯的方向,凱文大叔列出以下幾個可調整的方向,未來要開發企業產品時可以做為開發項目
List<Message> 的方式傳送就能區分今天的內容就到這,不過大家有沒有想過為何存入聊天訊息後會自動計算向量?
資料庫跟程式都無法幫你算出向量,這部分其實要仰賴 Embedding Model
明天我們就來詳細介紹
今天學到了甚麼?
最後再提醒一次因為引入了 Docker Componse Support,Docker Desktop 要先啟動才能執行程式
程式碼下載: https://github.com/kevintsai1202/SpringBoot-AI-Day22.git
凱文大叔使用 Java 開發程式超過 20 年,對於 Java 生態非常熟悉,曾使用反射機制開發 ETL 框架,對 Spring 背後的原理非常清楚,目前以 Spring Boot 作為後端開發框架,前端使用 React 搭配 Ant Design
下班之餘在 Amazing Talker 擔任程式語言講師,並獲得學員的一致好評
最近剛成立一個粉絲專頁-凱文大叔教你寫程式 歡迎大家多追蹤,我會不定期分享實用的知識以及程式開發技巧
想討論 Spring 的 Java 開發人員可以加入 FB 討論區 Spring Boot Developer Taiwan
我是凱文大叔,歡迎一起加入學習程式的行列


 iThome鐵人賽
iThome鐵人賽